Vova's Blog
I write about machine learning and finance
Multi-Arm Bandits for Recommendation Systems
by Vladimir
Envision yourself as a store owner looking to boost foot traffic. You hatch a plan: stand at the front and actively promote your items to those walking by. With enthusiasm, you quickly wear a striking outfit and hold up a blank board, ready to publicize a special deal. However, when it's time to pen the actual offer, you're stumped. A "10% discount on everything" could work, but you're torn between it being too small to matter or too large to remain profitable. A flat "$2 off your initial buy" crosses your mind, but could this be overly generous for just any passerby? Then the idea of "Free gift with every purchase" springs forth. It's intriguing, but will it genuinely enhance the day's revenue?
You quickly realize that what you truly need is some sort of method, capable of predicting the most appealing offer for each potential customer.
Welcome to the intricate and intriguing realm of recommendation systems, where algorithms help to match the right offer to the right customer, improving your chances of conversion and sales.
Recommendation systems is all about data
When we talk about recommendation systems, we talk big data! Abundance of data ensures a higher level of confidence about user preferences. In contrast, when there is limited data, there is a lack of certainty about what users might prefer. However, even in the face of such uncertainty, recommenders tend to prioritize and suggest items that have received a higher level of engagement previously.
For instance, with collaborative filtering, a most popular method typically used by recommender systems, users are matched based on their past behaviors or ratings. A user may be recommended a movie that other similar users have enjoyed.

Meanwhile, item-based similarity approaches would recommend items that are similar to ones the user has previously interacted with or rated highly. For instance, if a user liked a certain science fiction book, they would be recommended other books in the same genre or by the same author.
However, these methods can contribute to a feedback loop, where items that aren't initially recommended continue to receive low to no engagement. This results in a cycle where those items that were initially popular and recommended continue to get promoted, while potentially relevant items get ignored. This might lead to the problem of overfitting, where only a limited set of items get recommended over and over, while a large variety of other potentially interesting items are not discovered or recommended. As a result, the system fails to explore the breadth of user preferences, limiting the overall user experience.
Mastering Multi-Arm Bandits
There are several approaches that can solve this type of overfitting, the Multi-Arm Bandits is one of the most powerful and commonly used ones. Bandit algorithms propose a solution to this feedback-loop problem by modeling uncertainty and intentionally exploring to minimize it. This strategy embodies the concept of 'exploration vs exploitation', where 'exploitation' is using the knowledge we already have to recommend the most engaging items, while 'exploration' involves suggesting less-known items to gather more information about user preferences.
By acknowledging the inherent uncertainty in the data, bandits actively engage in exploration to reduce it, thereby learning about the potential relevance of previously unexplored or underexplored items. For instance, instead of continually recommending the best-performing item (a best-selling menu item, for example), a bandit algorithm might occasionally recommend a less popular item (perhaps a new item or previously unpopular). This explorative approach provides an opportunity to discover whether users might like this less-known item, thereby expanding the scope of recommendations.
Moreover, bandits incorporate a system of rewards, where a successful recommendation (like a user clicking on a recommended item) garners a 'reward'. Over time, these rewards inform the algorithm about the likelihood of different items being appreciated by different users, further refining the recommendation process. This harmonious blend of uncertainty, exploration, and learning makes bandit algorithms a compelling approach to mitigating the issues prevalent in the realm of recommendation systems.
Reward is usually denoted as $ R_t $
Every time an action is taken a reward is obtained. Each time an action is taken the reward returned can have a different value.
Below is few more definition that are used to define the Bandit model:
- The number of available actions is denoted by the letter $ k$
- Action: the action taken at time-step $ t$ is denoted as $ A_t$
- Each of the available $ k$ actions has an expected reward: Q(a):
$$Q(a) = E[R_t | A_t = a]$$
The most simple example of the reward function is a Sample Average Estimates:
$$Q_{t+1}(a) = \frac{1}{n} \sum_{i=1}^{n} R_i$$
Choosing The Right Bandit
Choosing different design of the reward function yield different types of Bandits.
In the following sections, we will touch upon three fundamental bandit algorithms: epsilon-greedy, Upper Confidence Bound (UCB), and Thomson Sampling.
- Epsilon-Greedy: This algorithm operates by using a probability $ ε$ to determine if it will explore or exploit. So, the reward function could be represented like:
$$R_t = \begin{cases} \text{argmax}_{a} Q_t(a), & \text{with probability } 1 - ε \\ \text{a random action}, & \text{with probability } ε \end{cases}$$
Where
- $ R_t$ represents the chosen action at time $ t$,
- $ Q_t(a)$ is the estimated value of action $ a$ at time $ t$, and
- $ ε$ is the probability of choosing to explore rather than exploit.
- Upper Confidence Bound (UCB): The UCB algorithm adds a confidence interval to the estimated reward for each action. The action chosen is the one with the highest upper confidence bound. This could be represented like:
$$A_t = \text{argmax}_{a} \left[ Q_t(a) + c \sqrt{\frac{\ln t}{N_t(a)}} \right]$$
Where $ A_t$ is the action chosen at time $ t$, $ Q_t(a)$ is the estimated value of action $ a$ at time $ t$, $ c$ is a constant determining the level of exploration, $ N_t(a)$ is the number of times action $ a$ has been chosen up to time $ t$, and $ l_n$ is the natural logarithm.
- Thomson Sampling.
In this algorithm, an action is chosen based on the highest sample from each action's reward distribution. This could be represented like:
$$A_t = \text{argmax}_{a} \left[ \text{Sample from } β(R_{1:t-1}(a), T_{1:t-1}(a)) \right]$$
Where $ A_t$ is the action chosen at time $ t$, $ β$ represents a Beta distribution (commonly used in Thompson Sampling when rewards are binary), $ R_{1:t-1}(a)$ is the sum of rewards for action $ a$ up to time $ t-1$, and $ T_{1:t-1}(a)$ is the total number of times action $ a$ has been chosen up to time $ t-1$.
Our primary focus will be on Thomson Sampling, as it frequently surpasses both epsilon-greedy and UCB algorithms in performance. For readers interested in delving deeper into each algorithm and exploring a comprehensive comparison between them, we've included pertinent links in the reference section.
Data For Bandits
Returning to our shopkeeper scenario, after acquiring a solid understanding of multi-arm bandits and different reward functions, our shopkeeper resolves to employ the Thompson Sampling technique to identify the optimal offer for each of his patrons. His store, being somewhat removed from the bustling main street, sees a regular flow of three individuals passing by daily - we'll denote these as Person $ P_1$, $ P_2$, and $ P_3$.
For each individual $ P_i$ (where $ i$ ranges from 1 to 3), there are five potential offers (or actions) that the shopkeeper could extend, denoted as $ a_1, a_2, \ldots, a_5$. Notably, he also posits that not all individuals may necessarily need an offer to visit the store. To verify this hypothesis, he decides to occasionally abstain from extending any offers at all, thereby establishing a control observation for his experiment.
With each passing day, the shopkeeper observes the interactions of each individual with the varying offers (including the no-offer scenario), aiming to discern the optimal action $ A_i$ for each person $ i$. This optimal action would not only encourage a higher frequency of store visits (improving conversion rates), but also exhibit an uplift over the control scenario of no offers. In doing so, the shopkeeper can ensure his marketing campaign is cost-efficient, only extending offers when they demonstrably enhance store visitation.
Defining The Learner
With a clear strategy in mind, the shopkeeper set forth on a two-month experiment. Each day, he displayed a distinct offer (or no offer at all) to each of the three individuals, and meticulously recorded the outcome or "reward" ($ R$) as either a conversion (1) or non-conversion (0):
$$R_{t,i,a} =
\begin{cases}
1 & \text{if conversion} \\
0 & \text{if non-conversion}
\end{cases}$$
In this formula, $ t$ denotes the time step or day index, $ i$ signifies the person, and $ a$ indicates the offer index.
The shopkeeper then updated the parameters of the Beta distribution for each person's offer preference using the following rules:
- $ \alpha_{t,i,a} := \alpha_{t-1,i,a} + R_{t,i,a}$ (representing the number of successes)
- $ \beta_{t,i,a} := \beta_{t-1,i,a} + (1 - R_{t,i,a})$ (representing the number of failures)
Here, $ \alpha_{t,i,a}$ and $ \beta_{t,i,a}$ denote the parameters of the Beta distribution for person $ i$, action $ a$ at time step $ t$.
These updates provided the shopkeeper an estimated conversion probability $ P_{i}(X|a)$ for each individual and offer. This probability followed a Beta distribution:
$$P_{i}(X|a) \sim \text{Beta}(\alpha_{t,i,a},\beta_{t,i,a})$$
Finally, to decide which offer to show next, the shopkeeper chose the action $a$ that yielded the maximum expected reward. He used the following strategy to select the action:
$$A_{t+1,i} = \text{argmax}_{a} \left[ \text{Sample from } \text{Beta}(\alpha_{t,i,a}, \beta_{t,i,a}) \right]$$
Running the Model
After two months of diligent experimentation, the shopkeeper had amassed a rich collection of data for each passerby, shedding light on their distinct preferences. The shopkeeper meticulously recorded a sequence of observations:
| customer_id | day_index | offer_index | success |
| 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 |
| 2 | 0 | 0 | 1 |
| 0 | 1 | 1 | 0 |
| 1 | 1 | 1 | 0 |
| 2 | 1 | 1 | 1 |
This table delineates the data he recorded. The day_index column begins from 0, representing the first day of the experiment. The customer_id could be either 0, 1, or 2, indicating the individual to whom an offer was presented. The offer_index reflects the specific offer shown - ranging from 1 to 5, with '-1' indicating a control experiment where no offer was presented. Finally, the success column is a binary marker showing whether the individual visited the shop after seeing the offer, with '1' indicating a visit and '0' representing no visit.
Armed with this data, the shopkeeper dusted off his seldom-used laptop and entered these records into a Jupyter Notebook to analyze and visualize the results. His analysis culminated in a series of animated plots demonstrating the convergence of the Beta distribution for each individual over time.
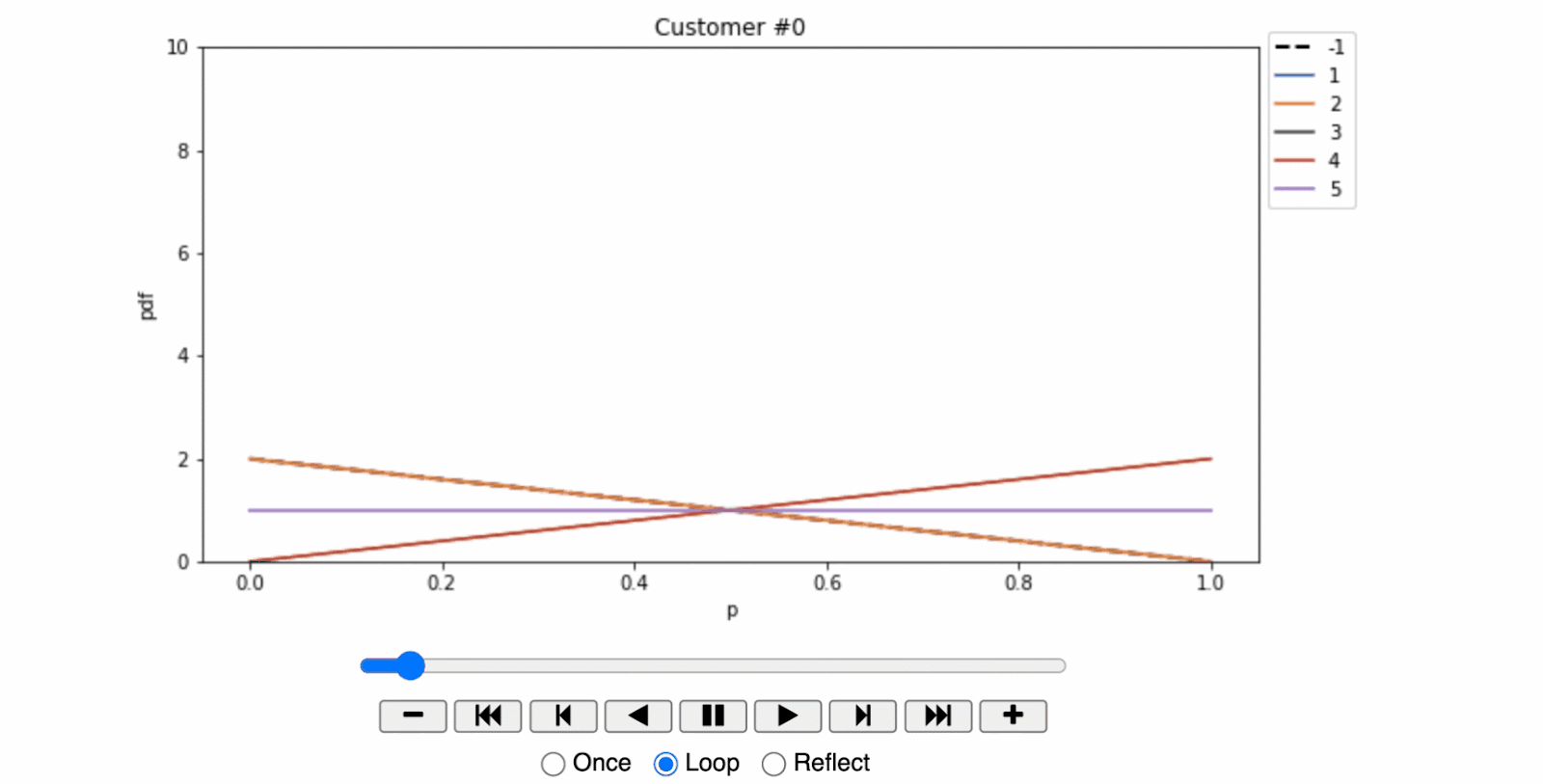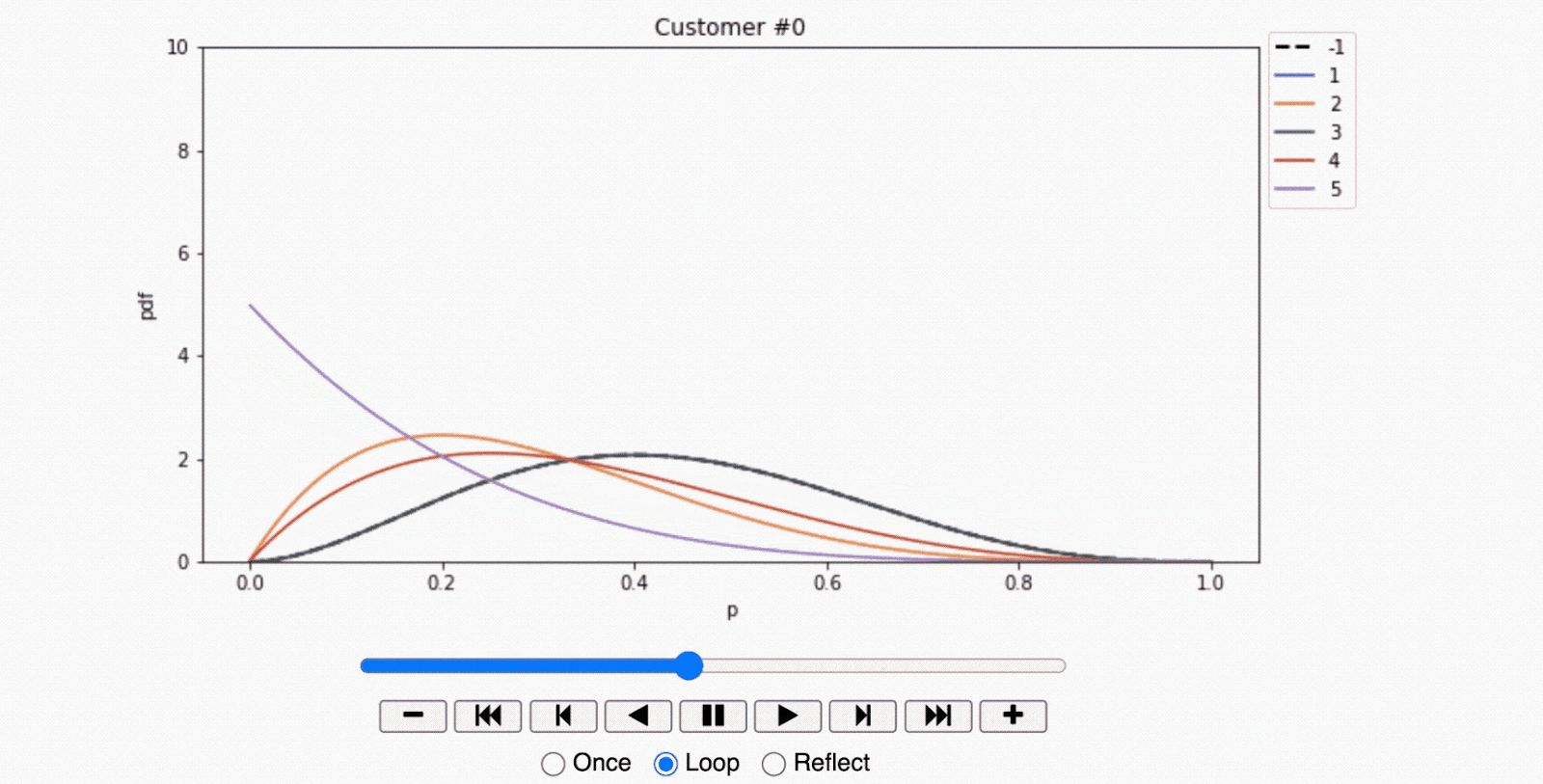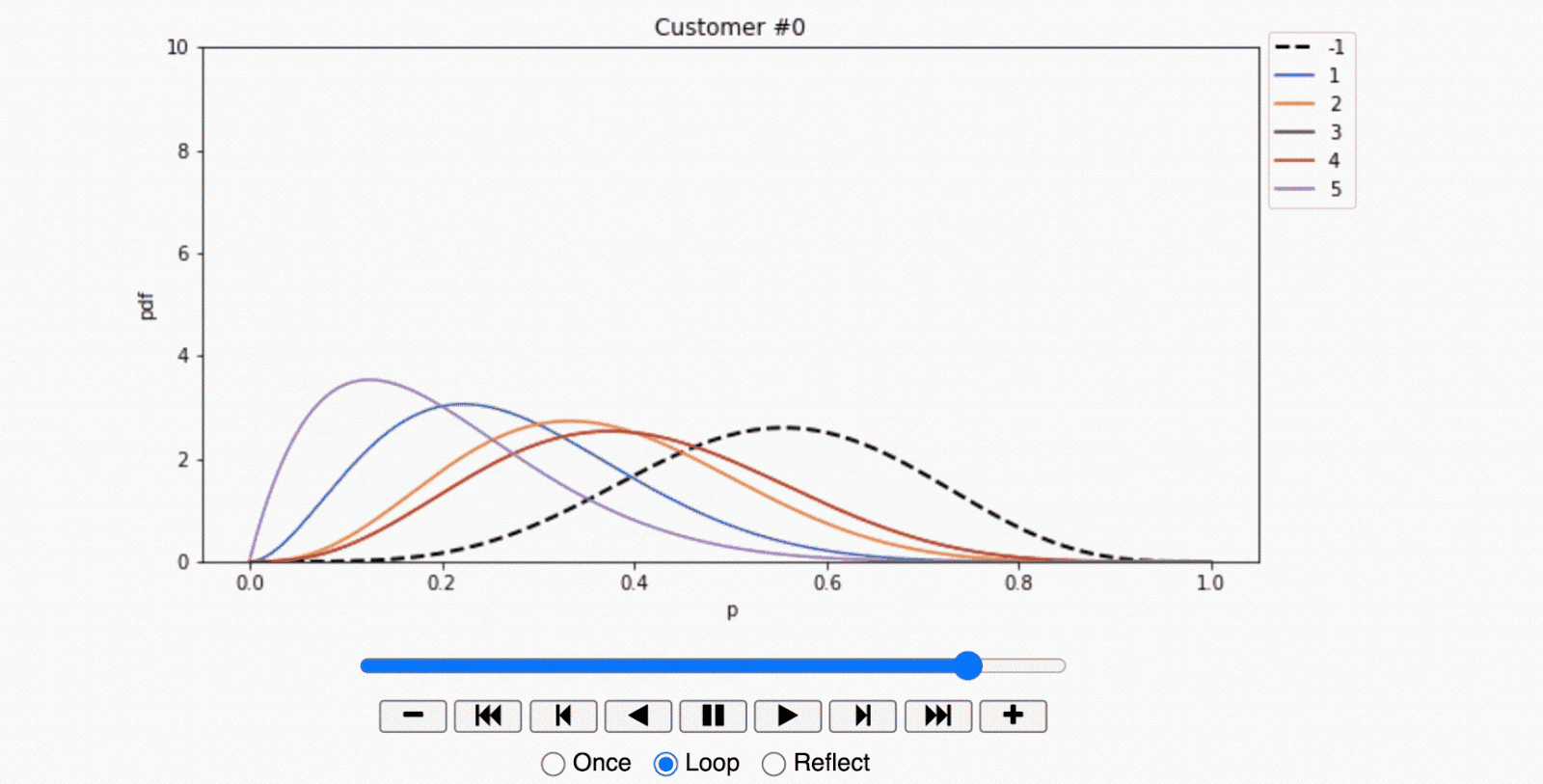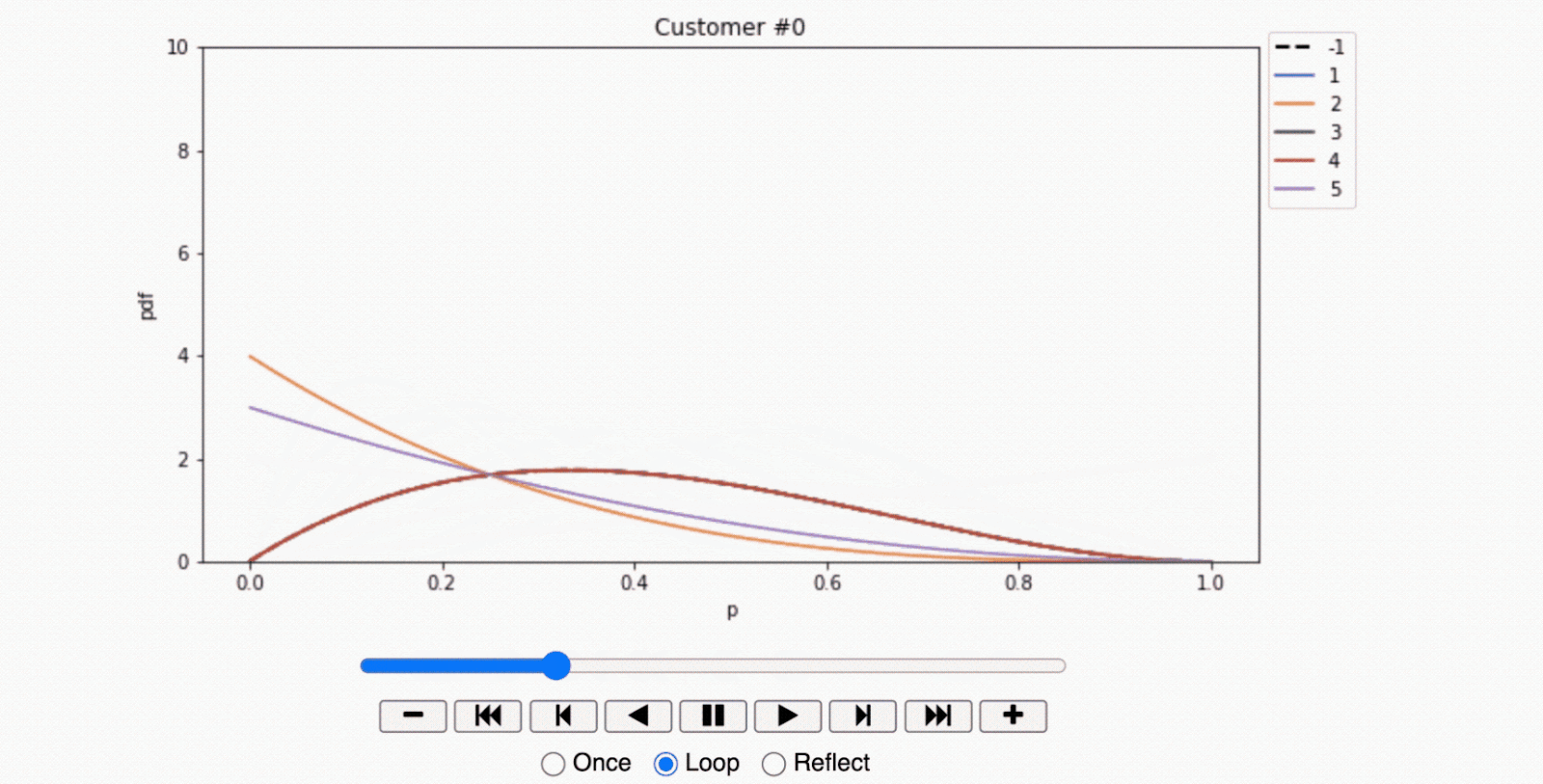
- For the first customer, the plot reveals a surprising trend. This customer demonstrated the largest response in the control observations, suggesting that the mere presentation of an offer discouraged them from entering the store. In marketing terminology, this segment of customers is known as 'sleeping dogs,' who are best left undisturbed.
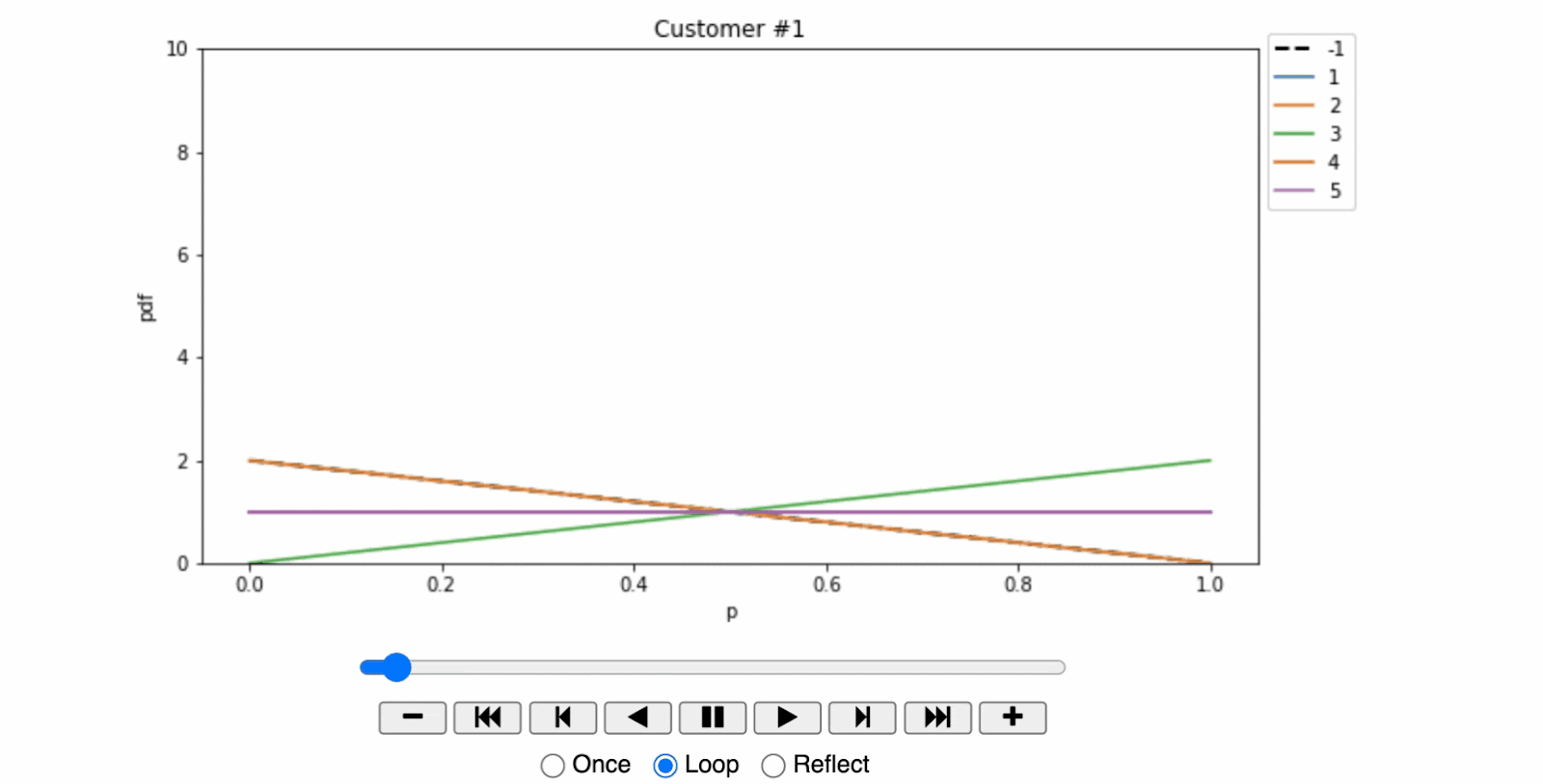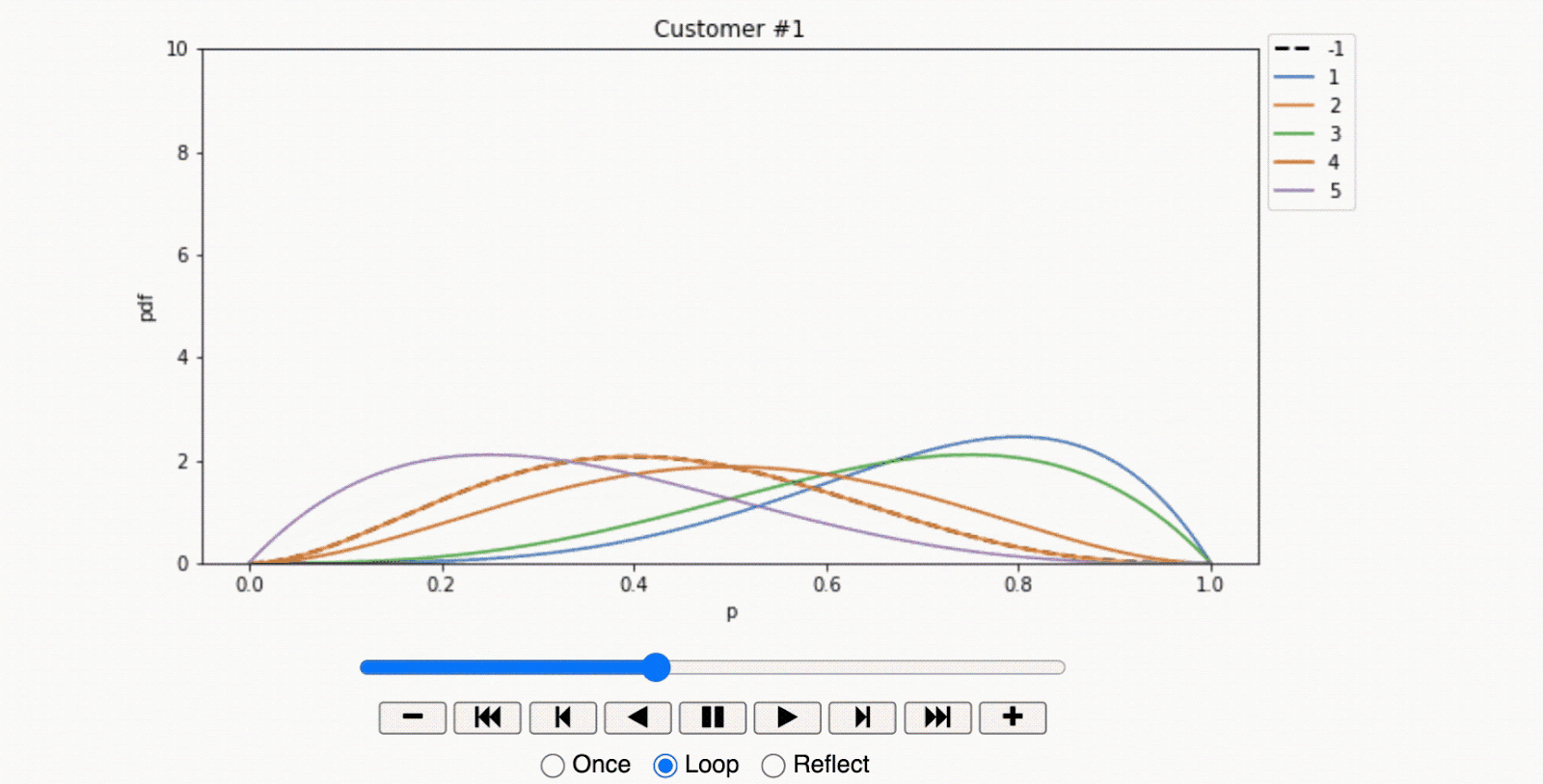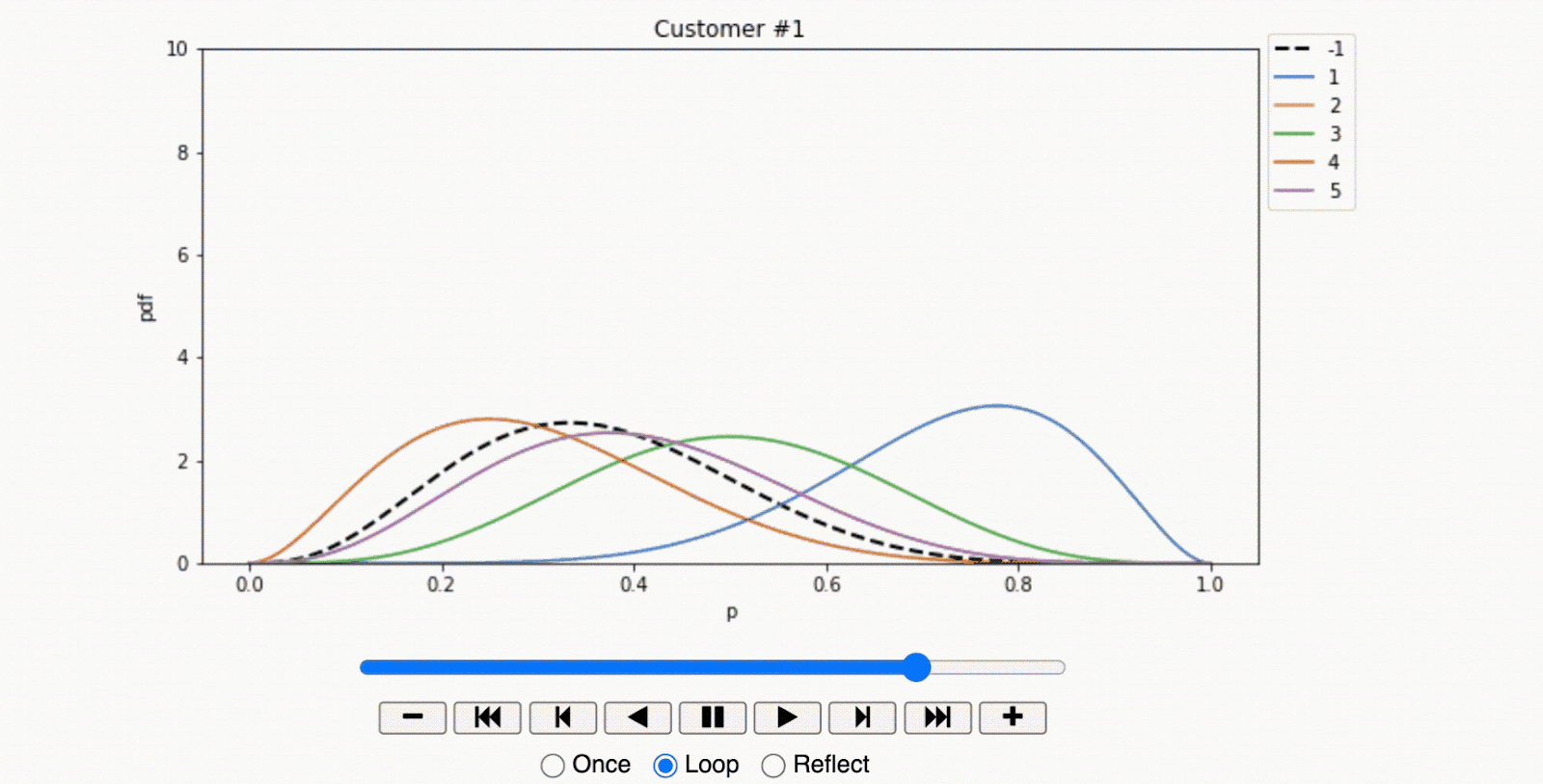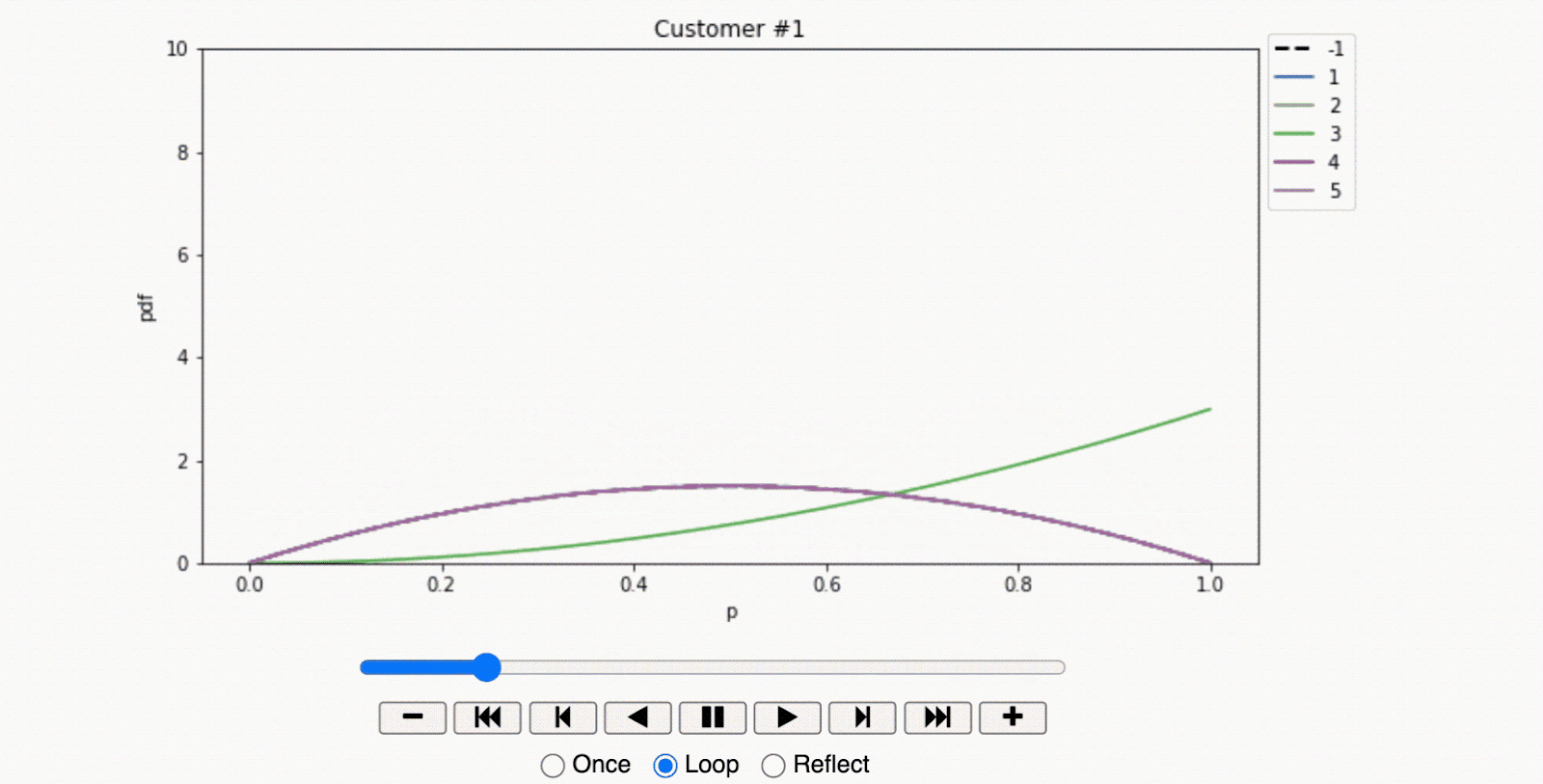
- In stark contrast, the second customer showed a strong preference for a specific offer. The offer $ a^{(1)}$ yielded a clear uplift in store visits compared to other offers and the control group. This data suggests that the individual was persuadable and therefore worth the investment in marketing efforts.
- The third customer, however, painted a completely different picture. The response rate was uniform across all offers, including the control group. This was a clear indication that regardless of the marketing efforts or offers, this individual's decision to visit the store remained unchanged. As such, including this individual in the target audience would not result in incremental net sales and would be an inefficient use of resources
Conclusion
In conclusion, the shopkeeper's innovative application of Thompson Sampling provided him with invaluable insights. It empowered him to tailor his marketing strategy for each individual customer, enhancing efficiency and cost-effectiveness.
By mapping customer responses to offers, he could discern the impact of different marketing efforts. This data-driven approach enabled more effective customer segmentation. Instead of a one-size-fits-all strategy, he could now tailor offers based on individual preferences, optimizing the value of his marketing budget.
Moreover, he could identify customers who remained unaffected by offers, thereby avoiding unnecessary marketing expenditure. On the flip side, he recognized customers who would purchase irrespective of promotions, saving resources on unneeded incentives.
In essence, the shopkeeper's strategic use of Thompson Sampling refined his marketing from broad-strokes to precision-guided. This case underscores the potential of machine learning algorithms in enhancing marketing effectiveness and customer segmentation while ensuring optimal return on marketing investment.
References
- “How to Build and Evaluate a Next Best Action Model,” Grid Dynamics Blog, July 29, 2021, https://blog.griddynamics.com/next-best-action-churn-prevention/.
- Prince Grover, “Various Implementations of Collaborative Filtering,” Medium, March 31, 2020, https://towardsdatascience.com/various-implementations-of-collaborative-filtering-100385c6dfe0.
- Guilherme Duarte Marmerola, “Thompson Sampling for Contextual Bandits,” Guilherme’s Blog, November 28, 2017, https://gdmarmerola.github.io//ts-for-contextual-bandits/.
- James McInerney et al., “Explore, Exploit, and Explain: Personalizing Explainable Recommendations with Bandits,” in Proceedings of the 12th ACM Conference on Recommender Systems, RecSys ’18 (New York, NY, USA: Association for Computing Machinery, 2018), 31–39, https://doi.org/10.1145/3240323.3240354.
- Eugene Yan, “Bandits for Recommender Systems,” eugeneyan.com, May 8, 2022, https://eugeneyan.com/writing/bandits/.
- Steve Roberts, “Multi-Armed Bandits: Part 1,” Medium, December 10, 2020, https://towardsdatascience.com/multi-armed-bandits-part-1-b8d33ab80697.
- “Beta Distribution,” in Wikipedia, July 27, 2023, https://en.wikipedia.org/w/index.php?title=Beta_distribution&oldid=1167451431.
Originally published on Grid Dynamics Blog