Vova's Blog
I write about machine learning and finance
Problem-Solving Principles Applied to Data Science
by Vladimir
Auguste Rodin, The Burghers of Calais, The Musée Rodin of Paris, France
Introduction
The field of Data Science is among the most diverse ones. It's relatively young and still in search for its shapes. It results that many problems require non-standard, out-of-the-box solutions.
Being a data scientist is like being a detective, but you deal with big, flat tables (and sometimes with people). You have an unknown, sometimes unformulated problem, and your goal is to deduce and derive the answer.
In this post, I will discuss the methods I employ when solving problems, which are not limited to a data science context. I hope that this information can be helpful to someone who is just starting out in the field or an experienced person who wants to explore a slightly different perspective on the topic.
Problem-solving is about creativity
And creativity is about generalization.
I've been told once that there are many good problem solvers in the field of data science who can apply very advanced methods and work with complex data—there is no real shortage of good executes in the field. But what is, in fact, a rare find is a strong data scientist with a creative mind. By that, I mean a person who would find a new approach to the problem, a surprising data perspective. At the end of the day, data is just a projection of reality onto our hard drives, and it's easy to get stuck in this projection.
Even though curiosity is natural for a human, it's a skill to systematically apply it to enhance your knowledge of the world and to build connections between seemingly unrelated topics. As one great mathematician once said:
A mathematician is a person who can find analogies between theorems; a better mathematician is one who can see analogies between proofs, and the best mathematician can notice analogies between theories. One can imagine that the ultimate mathematician is one who can see analogies between analogies.
Stefan Banach
My understanding of this quote is that "analogies between analogies" is a rephrased generalization.
Generalized knowledge forms a broad outlook, is the highest-quality knowledge that can exist, and is a key to any new discovery! Liberal arts facilitates the generalization of knowledge; it teaches you creativity and active thinking. If force, you create a habit of idea fusion and examples of how the same underlying principle (model) can work in very different contexts.
I remember several times I found an inspiration or cross-reference to the data science problem while reading through a fiction book. Our world is filled with different models: some of them based on big enough dataset, some aren't, but these models can still be useful.
So don't descriminate fiction and liberal arts in general, it's not a waste of time for techy, it's a practice in creativity, practice in problem-solving.
Analytics is like debugging
Analysis is like debugging
-Edward Schwalb
With a background in computer science, this is quite intuitive for me. You have a complex system you want to understand, tweak, and eventually affect. You want to find, isolate, and control most factors affecting the outcome. The nature is quite ironical, and usually, you don't have direct access to the most important factors, at most to some proxy metrics of them. It's not necessarily a bad thing per se, but you must be aware of what limitations it brings to your model.
Start Simple
As a data scientist, you'll often approach an open-ended, loosely defined problem that may not be firmly formulated. There'll be many possible paths to proceed with the exploration, and it's so easy to get lost in the woods of theories that look so appealing and attractive that it's hard to resist following them. Leave that alone, and you'll quickly find yourself completely lost and overwhelmed with theories that can explain every possible outcome. To avoid that, data scientists should think of themselves as "detectives" and follow the rigorous rules:
- Ask the most simple question
First, find out the most simple question you can find a reliable answer to. It may be something as trivial as "What data do we have?" or
- Start with the situation when you have the most information.
When you get answers to your questions, identify the area where you have the most information. This would be your starting point in the analysis. By testing your hypotheses, there'll be fewer chances for confusion and messing with facts
- Find something that you can prove working and then reduce the search space
This means paying precise attention to the feedback of your tests. Even the most simple model whose effect size is higher than the variance can tell a lot about the environment that you study and can give a hint about where to move next.
- Use Occam's razor to illuminate sophisticated questions/explanations.
This is practically the return to point #1 - stick with the simplest explanation. With more data available and more experiments conducted, you'll be tempted to find a more "elegant," more "sophisticated" explanation for your subject. Be cautious: in two competitive hypotheses, cut off the one that has more assumptions or parameters... Unless you can find more data to justify it.
Optimizing data brings more benefits than optimizing the model
Most of the time, data scientists would spend unproductive trying to optimize the model.
Part of the reason why using cleverer algorithms has a smaller payoff than you might expect is that, to a first approximation, they all do the same.
I like this quote from the "A Few Useful Things to Know About Machine Learning" [1] article:
All learners essentially work by grouping nearby examples into the same class; the key difference is in the meaning of "nearby".
With nonuniformly distributed data, learners can produce widely different frontiers while still making the same predictions in the regions that matter (those with a substantial number of training examples and, therefore, also where most test examples are likely to appear). This also helps explain why powerful learners can be unstable but still accurate.
Easily, the most crucial factor is the features used. Learning is easy if many independent features correlate well with the class. On the other hand, if the class is a very complex function of the features, you may not be able to learn it.
All models are wrong, but some are useful
This is at the core of our business. You will never get a perfect model, but you don't even need one. What you need is an understanding of what imperfect model can be applied in a particular situation.
A simple example is Linear Regression. It is quite a strong tool for analysis despite its simplicity.
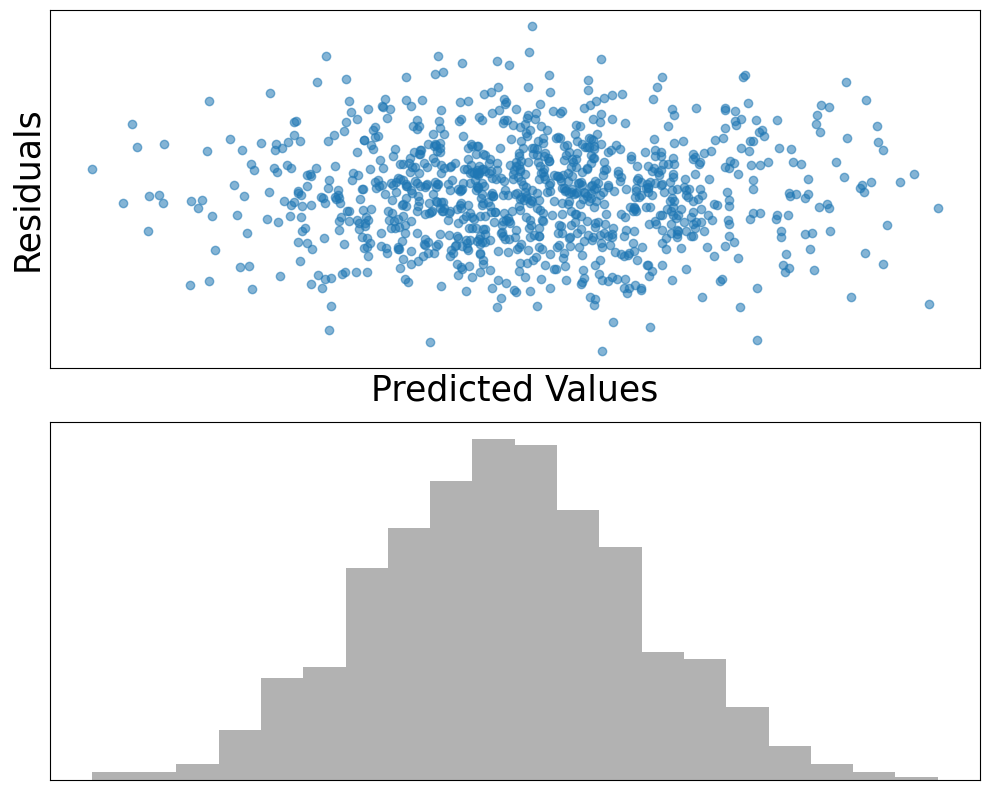
The important part is that if you know that residuals of your model are normal (i.e., your estimator is unbiased), you can be sure that if applied at scale, errors of your model would tend to cancel each other out. This is a special case of the realization of the Central Limit Theorem and its power.
Modeling key principle
You must know when the model works and doesn't and what limitations.
Make sure your model's metric is represented in the online data. Whatever metric you use, make sure to evaluate it during the model serving.
This is, at the same time, the most simple and the most complicated principle in machine learning. When you train the model, you have full control over the data you feed to it, and the model learns the corresponding distribution. But when the model is deployed to production, it is left on the mercy of what data will be passes to it. If it significantly different from what has been seen, and the model has some non-linear components, it can produce unstable and unexpected prediction. This is known as data drift. I can re-state this principle as "if something goes wrong, checking the data, it's probably the cause, and only then check the model".
The sophistication of the algorithm is rarely the limiting factor
In AI applications, the sophistication of the algorithm is rarely the limiting factor. The quality of the design, the data, and the people that make up the system all matter more.
Data scientists should be a good speaker
I've proven many times that an unsophisticated project with a convincing story and well-crafted deck will outgrow advanced projects that you have trouble pitching. Even a simple visualization can go a long way.
In other words, prepare presentations for all your projects and keep these decks organized. Even if you fail to sell your project at first, there will certainly be another opportunity with better circumstances, and having a deck ready can be paramount.
Conclusion
In this article, I outlined some of the key principles I developed as a data scientist. Not all of them are strict rules or necessary checkmarks, but rather guidance that I follow on a daily basis. This post wasn't filled with technical details, as one may expect. Even though tech details are the actual material components of machine learning, the approach and strategy of applying them define the quality of the resulting effect.
By adopting these principles in your data science work, you can streamline your process, avoid common mistakes, and ultimately create more effective, robust models.
If you have any questions, thoughts, or principles of your own to share, please leave a comment below. I'd love to hear from you and learn from your experiences as well.
For those interested in diving deeper into these principles and other data science topics, I invite you to check out my upcoming meetup called "AI/ML Conversations" where we'll explore these concepts in greater depth. It happens in-peson in NYC and online via Zoom.
It's a fantastic opportunity to connect with other data science enthusiasts, learn from expert speakers, and share your own insights. Looking forward to seeing you there! We are open to speakers, so feel free to reach out to me on LinkedIn, or use this form to submit your proposal.