Vova's Blog
I write about machine learning and finance
University Towns and Recession risk
by Vladimir
The time has come for me to start looking for new apartments in the US. The logical question has
appeared: What is the best area to rent/buy an apartment?
The simplest answer is "Go call your realtor and ask this question to him/her!." However, I decided to think a bit independently. Here is the first part of my housing price analysis research.
First thing first, I feel lucky to get a job not far from one big university's campus. It means if I get an apartment in university town it'll be a convenient to drive to work and home without traffic and in shortest time.
But does it give any benefits to rent/buy an apartment in university city? One of the variables which should be disclosed is a correlation between price volatility and GDP. The 2008 crisis had teached us that it could pass a decade before the real estate price can come back to the pre-crisis level. As the real estate prices now near those all-time-high levels again it would be a shame to buy at the highest price just before the new recession.

Since price in university cities depend more on school's costs and the vast majority of renters is students, the housing price supposes to be less sensitive to the entire real estate market.
Here is the primary hypothesis:
"University towns have their mean housing prices less affected by recessions."
To prove or refute this hypothesis I'll calculate a p-value for university and not-university cities price ratio correlation.
Price ratio calculated by this formula:
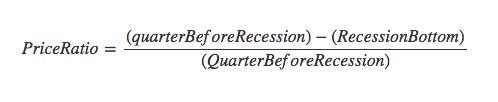
To separate university cities form US cities list entirely, I used this List of college towns form Wikipedia.
(1) I've start with some data cleaning in IPython(Jupyter Notebook):
Un_sity= pd.read_table('university_towns.txt', header=None)
tmp = ''
deldubl= False
Un_sity[1] = [0 for i in range(len(Un_sity))]
for i in range(len(Un_sity)):
if '[edit]' in Un_sity.iloc[i,0]:
tmp= Un_sity.iloc[i,0].split('[')[0]
Un_sity.iloc[i,1] = tmp
if '(' in Un_sity.iloc[i,0]:
Un_sity.iloc[i,0] = Un_sity.iloc[i,0].split('(')[0]
Un_sity.columns = ["RegionName","State"]
Un_sity['RegionName'] = Un_sity['RegionName'].apply(lambda x: x.strip(' '))
Un_sity = (Un_sity[Un_sity.RegionName.str.contains('[edit]') == False]
.reset_index(drop=True))
col = Un_sity.columns.tolist()
col = col[-1:] + col[:-1]
Un_sity = Un_sity[col]
return Un_sity
(2) Here's what comes out:
get_list_of_university_towns()
Out[8]:
| State | RegionName | |
|---|---|---|
| 0 | Alabama | Auburn |
| 1 | Alabama | Florence |
| 2 | Alabama | Jacksonville |
| 3 | Alabama | Livingston |
| 4 | Alabama | Montevallo |
| 5 | Alabama | Troy |
| 6 | Alabama | Tuscaloosa |
| 7 | Alabama | Tuskegee |
| 8 | Alaska | Fairbanks |
| 9 | Arizona | Flagstaff |
| 10 | Arizona | Tempe |
| 11 | Arizona | Tucson |
| 12 | Arkansas | Arkadelphia |
(3) After I composed historical GDP to list of all US cities with primary key structure [State][CityName]:
| 2015q2 | 2015q3 | 2015q4 | 2016q1 | 2016q2 | 2016q3 | ||
|---|---|---|---|---|---|---|---|
| State | RegionName | ||||||
| New York | New York | 5.408000e+05 | 5.572000e+05 | 5.728333e+05 | 5.828667e+05 | 5.916333e+05 | 587200.0 |
| California | Los Angeles | 5.381667e+05 | 5.472667e+05 | 5.577333e+05 | 5.660333e+05 | 5.774667e+05 | 584050.0 |
| Illinois | Chicago | 2.060333e+05 | 2.083000e+05 | 2.079000e+05 | 2.060667e+05 | 2.082000e+05 | 212000.0 |
| Pennsylvania | Philadelphia | 1.179667e+05 | 1.212333e+05 | 1.222000e+05 | 1.234333e+05 | 1.269333e+05 | 128700.0 |
| Arizona | Phoenix | 1.741667e+05 | 1.790667e+05 | 1.838333e+05 | 1.879000e+05 | 1.914333e+05 | 195200.0 |
| Nevada | Las Vegas | 1.816000e+05 | 1.867667e+05 | 1.906333e+05 | 1.946000e+05 | 1.972000e+05 | 199950.0 |
(4) Then, using (2) table, I separated "university cities" and "not-university cities" to make the analysis easies:
| 2008q3 | 2008q4 | 2009q1 | 2009q2 | 2009q3 | 2009q4 | 2010q1 | |
|---|---|---|---|---|---|---|---|
| type | |||||||
| University city | 204965.392520 | 201176.120016 | 198745.582822 | 195525.336597 | 192207.414141 | 190618.258767 | 189493.623361 |
| NOT University city | 239272.003013 | 233714.631548 | 230301.692866 | 225910.234464 | 220984.097050 | 218951.894839 | 217091.016083 |
| GDP | 14891.600000 | 14577.000000 | 14375.000000 | 14355.600000 | 14402.500000 | 14541.900000 | 14604.800000 |
In (3) and (4) tables I show only a couple of columns form entire table because it too wide to input in this post. The full
observed range is within 01.01.2000 - 10.01.2016
observed range is within 01.01.2000 - 10.01.2016
(5) Now, let's make a simple visualization of (4) table with highlining in price performance over the recession period:

The left axis shows the average price of real estate in the US:
Light-green bars - avg. Price of Not-University cities, dark-green bars - avg. Price of University cities.
The red line shows the US GDP.
The red line shows the US GDP.
As we can see, during the recession period the price on not-university cities was falling faster than the price
in university cities.
in university cities.
(6) It appears clearly if show spread between University and Not-University cities compared to GDP:

In this chart light-green area is US GDP and the black line is price spread between University and Not-University cities.
(7) Finally, Let's run a T-Test (Student's T-Test) to understand the statistical significance of this data.
def is_test_true(): if p_val < 0.01: return True else: return False def is_better(): if not_uni.mean() < is_uni.mean(): return 'non-university town' else: return 'university town' df, not_uni, is_uni = cut_to_cohort('2006q4','2009q2') p_val = list(ttest_ind(not_uni,is_uni))[1] return (is_test_true(),p_val,is_better()) run_ttest()
Out[26]:
(True, 1.7900059546810142e-05, 'university town')
As we can see, the p-value is about 0.0000179005 what is significantly lower than 0.01( the limit value)
Thus, we can assume, that renting an apartment in University area is less risky that in every other place.
Now, when it came out that buying an apartment near a campus gives some benefits, I can search for offers
in some specific areas and be sure that my real estate will be more secured from recession and price volatility.
in some specific areas and be sure that my real estate will be more secured from recession and price volatility.
In the next part, I'll describe my pattern recognition model in local housing prices.
Source code of this research can be found on my GitHub.